분산분석은 분산을 통해
3개 이상의 집단의 모평균을 비교하기 위해 사용합니다.
하나의 요인에 근거하여 분석하는 경우
일원배치 분산분석(One-way ANalysis Of VAriance)이라고 합니다.
두 개의 요인에 근거하여 분석하는 경우
이원배치 분산분석(Two-way ANalysis Of VAriance)이라고 합니다.
세 개 이상의 요인에 근거하여 분석하는 경우
다원배치 분산분석(Multi-way ANalysis Of VAriance)이라고 합니다.
예제를 통해 일원배치 분산분석을
단계적으로 분석해보도록 하겠습니다.
A, B, C 세 초등학교 학생을 임의로 추출하여,
일주일 평균 운동시간을 측정한 결과는 다음과 같습니다.


A초등학교는 자교 학생의 평균 운동시간이
다른 두 초등학교보다 많기 때문에,
다른 두 초등학교보다 학생들의 건강에 더 신경쓰고 있다고 주장합니다.
이러한 주장은 통계적으로 타당할까요?
<일원배치 분산분석 1단계> 귀무가설과 대립가설 설정
학교 간 차이가 없다고 생각되었으나,
차이가 있다는 새로운 주장을 한다면,
기존의 주장과는 대립되므로 대립가설이라고 합니다.
만약 대립가설이 타당하지 않다면,
기존의 주장으로 돌아가게 되므로, 기존의 주장을 귀무(歸無)가설이라고 합니다.
돌아갈 귀(歸)와 없을 무(無)의 귀무이며,
돌아가서 보니 변한 건 없다는 의미입니다.
예제의 귀무가설은 다음과 같습니다.
세 초등학교 학생의 일주일 평균 운동시간은 모두 같다.
예제의 대립가설은 다음과 같습니다.
세 초등학교 학생의 일주일 평균 운동시간이 모두 같은 것은 아니다.
<일원배치 분산분석 2단계> 유의수준 설정
일반적으로 발생할 확률이 5%도 채 되지 않는다면,
통계적으로는 발생할 확률이 없다고 판단합니다.
이때 기준이 되는 확률이 바로 유의수준입니다.
만약 세 초등학교 학생의 일주일 평균 운동시간은 모두 같다고 가정한
귀무가설이 사실일 확률이 5% 이내라면,
귀무가설을 받아들이지 않기로 하겠습니다.
우리는 각 학교의 평균 운동시간을 비교하는 중이며,
차이가 없다고 가정한 귀무가설의 발생확률이 5%도 되지 않는다면,
귀무가설을 받아들이지 않는 것이 타당하기 때문입니다.
<일원배치 분산분석 3단계> 제곱합 계산
분산분석의 기본은 분산분석표를 작성하는 일입니다.
분산분석표를 통해 제곱합, 자유도, 평균제곱, F값을 구한 후
F값을 기각치와 비교하여 통계적 판단을 내리게 됩니다.
분산분석표 작성의 첫번째 단계인 제곱합을 계산하겠습니다.
제곱합은 제곱들을 더한다는 의미입니다.
여기서 제곱은 각각의 값과 평균과의 차이를 의미합니다.
A초등학교의 예를 들면 다음과 같습니다.
A초등학교의 값은 20, 19, 15가 있으며,
A초등학교의 평균은 18입니다.
A초등학교 제곱합은 다음과 같습니다.
(20 - A초등학교 평균)² + (19 - A초등학교 평균)² + (15 - A초등학교 평균)²
파이썬을 통해 구하면 다음과 같습니다.

numpy를 활용하며,
A의 값들에서 순서대로 하나씩 가져와서,
A의 평균(np.mean(A))을 뺀 후,
제곱(**2)하고,
np.sum을 통해 모두 더하여 제곱합을 구합니다.
B초등학교와 C초등학교도 동일한 방식으로 구합니다.

이는 각 초등학교 그룹 내의 차이를 구한 것입니다.
이러한 차이를 그룹내 변동이라고 합니다.
통계학에서는 이를
SSE(Sum of Squared Error),
RSS(Residual Sum of Squares),
SSW(Sum of Squares Within)로 다양하게 부르고 있으나,
분산분석에서는 그룹 '내'의 변동이라는 측면이 중요합니다.
예제의 그룹내 변동은
각 그룹내의 제곱합을 더한 100(14+78+8)이 됩니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | |||||
| 그룹내 변동 | 100 | ||||
| 총 변동 |
분산분석에서의 제곱은
각각의 값과 평균과의 차이를 의미한다고 하였습니다.
여기서의 평균은 세 초등학교의 평균만 있는 것은 아닙니다.
바로 세 초등학교 전체의 평균도 있습니다.
전체평균은 다음과 같습니다.

세 초등학교 전체의 제곱합은 다음과 같습니다.

이는 모든 값들과 전체 평균과의 차이를 구한 것입니다.
이러한 차이를 총변동이라고 합니다.
통계학에서는 이를
SST(Sum of Squares Total),
TSS(Total Sum of Squares),
총제곱합 등으로 다양하게 부르고 있으나,
분산분석에서는 '모든' 그룹의 변동이라는 측면이 중요합니다.
예제의 총 변동은 119.875입니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | |||||
| 그룹내 변동 | 100 | ||||
| 총 변동 | 119.875 |
지금까지 초등학교 내의 제곱합과,
세 초등학교 전체의 제곱합을 구하였습니다.
이제 가장 중요한 제곱합을 구해야 합니다.
분산분석의 목적은 그룹간 비교를 하는데 있기 때문입니다.
예제의 그룹은 각 초등학교이며,
각 초등학교의 평균과 전체평균과의 차이에 대한
제곱합을 구해야 합니다.
우선 각 초등학교의 평균과 전체평균과의 차이에 대한 값들은
다음과 같습니다.

for문을 활용하여 각 초등학교의 값들을 하나씩 i로 불러와서
np.mean을 활용해 각각의 평균을 구하고,
여기에 전체평균(np.mean(total))을 뺀 후,
제곱(**2)하여 구합니다.
다만 여기서 주의할 점은,
이렇게 구해진 값들을 그대로 더하면 안된다는 점입니다.
각 초등학교마다 조사한 학생 수가 다르기 때문에,
각각의 값에 각 초등학교별로 조사한 학생 수를 곱해야 합니다.
초등학교별로 조사한 학생 수는 다음과 같습니다.

이제 앞서 구한 각 초등학교의 평균과 전체평균과의
차이에 대하여 제곱한 값들에
각 초등학교별로 조사한 학생 수를 곱한 후,
더해줍니다.

이러한 차이를 그룹간 변동이라고 합니다.
통계학에서는 이를
SSB(Sum of Squares Between),
BSS(Between Sum of Squares),
ESS(Explained Sum of Squares),
처리 제곱합 등으로 다양하게 부르고 있으나,
분산분석에서는 그룹 '간' 변동이라는 측면이 중요합니다.
예제의 그룹간 변동은 19.875입니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | 19.875 | ||||
| 그룹내 변동 | 100 | ||||
| 총 변동 | 119.875 |
그룹간 변동과 그룹내 변동을 더하면 총 변동이 됩니다.
<일원배치 분산분석 4단계> 자유도 계산
이제 그룹간 변동, 그룹내 변동, 총 변동에 대한
자유도를 구합니다.
그룹간 변동의 자유도는
총 그룹 수(3)에서 1을 뺀 2가 됩니다.
그룹내 변동의 자유도는
각 초등학교에서 조사한 학생 수에서
1을 뺀 값들을 더하여 구합니다.
A초등학교에서 조사한 학생 수(3)에서 1을 빼고,
B초등학교에서 조사한 학생 수(3)에서 1을 빼고,
C초등학교에서 조사한 학생 수(2)에서 1을 뺀 값들을
모두 더하면 5(2+2+1)가 됩니다.
총 변동의 자유도는
그룹간 변동의 자유도와
그룹내 변동의 자유도를 더한 값이며,
예제에서는 7이 됩니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | 19.875 | 2 | |||
| 그룹내 변동 | 100 | 5 | |||
| 총 변동 | 119.875 | 7 |
자유도에 대해서는
다음 글을 참조 부탁드립니다.
[python/파이썬] 카이제곱분포로 가는 표본분산 분포의 평균
카이제곱분포, t분포, F분포는 모두 일정한 규칙에 따라 검정을 하기 위한 확률분포입니다. 통계적 가설을 검정하고, 검증된 가설은 통계적으로 유의미한 가설이 되며, 진리에 다가가기 위한 열
gilber.tistory.com
<일원배치 분산분석 5단계> 평균제곱 계산
평균제곱은 제곱합을 자유도로 나누어 구합니다.
자유도로 나누어 주는 이유는
표본분산의 식에서 유래합니다.
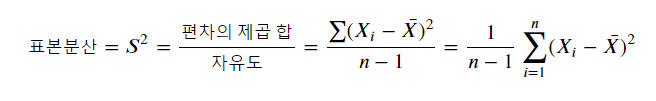
수식의 상세한 의미에 대해서는
다음 글을 참조 부탁드립니다.
[python/파이썬] 카이제곱분포로 가는 표본분산 분포의 평균
카이제곱분포, t분포, F분포는 모두 일정한 규칙에 따라 검정을 하기 위한 확률분포입니다. 통계적 가설을 검정하고, 검증된 가설은 통계적으로 유의미한 가설이 되며, 진리에 다가가기 위한 열
gilber.tistory.com
각각의 제곱합을 자유도로 나눈
평균제곱은 다음과 같습니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | 19.875 | 2 | 9.9375 | ||
| 그룹내 변동 | 100 | 5 | 20 | ||
| 총 변동 | 119.875 | 7 |
평균제곱은 영어로 MS(Mean Square)라고 하며,
그룹간 변동에 대한 평균제곱은 MSB(Mean Square Between),
그룹내 변동에 대한 평균제곱은 MSW(Mean Square Within)라고 합니다.
<일원배치 분산분석 6단계> 검정통계량 F값 계산
검정통계량 F값은
그룹간 변동에 대한 평균제곱 MSB를
그룹내 변동에 대한 평균제곱 MSW로 나누어서 구합니다.
검정통계량으로 F값을 사용하는 이유는
F분포가 두 분산의 비율을 검정하는 확률분포이기 때문입니다.
F분포에 대해서는
아래글을 참조 부탁드립니다.
[python/파이썬] F분포
카이제곱분포, t분포, F분포는 모두 일정한 규칙에 따라 검정을 하기 위한 확률분포입니다. 통계적 가설을 검정하고, 검증된 가설은 통계적으로 유의미한 가설이 되며, 진리에 다가가기 위한 열
gilber.tistory.com
검정통계량 F값은 다음과 같습니다.
| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | 19.875 | 2 | 9.9375 | 0.496875 | |
| 그룹내 변동 | 100 | 5 | 20 | ||
| 총 변동 | 119.875 | 7 |
<일원배치 분산분석 7단계> 기각치 계산
우리는 유의수준을 5%로 결정하면서,
세 초등학교의 평균 운동시간이 모두 같다고 가정한
귀무가설이 발생할 확률이 5%도 되지 않는다면,
해당 귀무가설을 받아들이지 않기로 하였습니다.
발생할 확률의 5%는
그래프 아래의 면적으로 확률을 정하는 확률분포의 면적이
5% 구간에 포함되는 경우입니다.
여기서 5%에 해당하는 영역을
기각역이라고 하며,
5% 구간이 시작되는 지점을
기각치라고 합니다.
다양한 확률분포가 있으나,
예제의 경우는 그룹간 변동과 그룹내 변동 사이에
분산의 비율을 통해 확률을 정의하는
F분포를 통해 확률을 정의합니다.
F분포의 그래프의 개형은 자유도에 따라 다릅니다.
비교하고자하는 두 분산의 자유도에 따라 달라지며,
예제의 경우 그룹간 변동의 자유도는 2이며,
그룹내 변동의 자유도는 5입니다.
따라서 자유도 2와 5을 따르는
F분포는 다음과 같습니다.

이 F분포의그래프의 아래 면적을 확률로 정의하므로,
왼쪽 영역은 상대적으로 발생할 확률이 높은 부분이며,
오른쪽 영역은 상대적으로 발생할 확률이 낮은 부분입니다.
분산분석은 그룹간 변동과 그룹내 변동을 비교하며,
그룹내 변동의 평균제곱을
그룹간 변동의 평균제곱으로 나누어
검정통계량을 구하였습니다.
따라서 이 검정통계량은 그룹간 변동이 커질수록,
큰 값을 가지게 됩니다.
그 값은 F분포의 그래프에서 x에 해당하며,
x의 값이 커질수록,
발생할 확률이 낮다는 것을 의미합니다.
정규분포와 t분포의 경우에는
예제에 따라서 그래프의 양측을 검정하거나,
한 측만 검정합니다.
F분포는 위와 같은 특성으로 인하여,
일반적으로는 오른쪽 한 측만 활용하여,
검정합니다.
다시 유의수준 5%로 돌아와서,
자유도 2와 5를 따르는
F분포의 기각역을 나타내면 다음과 같습니다.

검정색으로 표시된 부분이 기각역입니다.
그래프 아래의 면적을 100%로 봤을 때,
5%에 해당하는 부분입니다.
이러한 기각역이 시작되는 부분이 기각치이며,
유의수준 5%이며,
자유도 2와 5를 따르는 F분포의 기각치는
다음과 같습니다.

| 변동 | 제곱합 | 자유도 | 평균제곱 | F값 | F분포 기각치 |
| 그룹간 변동 | 19.875 | 2 | 9.9375 | 0.496875 | 5.786135 |
| 그룹내 변동 | 100 | 5 | 20 | ||
| 총 변동 | 119.875 | 7 |
<일원배치 분산분석 8단계> 통계적 판단
세 초등학교의 평균운동시간이 같다고 가정한
귀무가설의 발생할 확률이 5%도 되지 않는다면,
귀무가설을 받아들이지 않기로 하였습니다.
그 5%에 해당하는 경우는
예제에서 계산한 F값이,
F분포의 기각치인
5.786135043349964를 넘어가는 경우에 한하여
귀무가설을 받아들이지 않기로 하였습니다.
예제의 검정통계량 F값은 0.496875이며,
F분포의 기각치는 약 5.786135이므로,
세 초등학교의 평균운동시간이 같다는
귀무가설을 채택합니다.
가설의 기각여부는 귀무가설을 중심으로 표현하지만,
결론은 대립가설을 기준으로 표현합니다.
따라서 이번 예제의 결론은 다음과 같습니다.
유의수준 5%에서 검정결과,
세 초등학교의 평균운동시간이 다르다는
대립가설을 기각합니다.
즉, 자교의 평균운동시간이 다른 두 초등학교에 비해 많으므로,
다른 초등학교에 비해 학생들의 건강에 더 신경쓰고 있다는
A초등학교의 주장은 통계적으로 맞지 않습니다.
일원배치 분산분석을 이해하기 위해
수식에 대입하여 풀었으나,
scipy를 활용해 검정통계량과
기각여부를 간단히 확인할 수 있습니다.

검정통계량은 위 계산결과 같이 0.496875가 나왔으며,
유의수준 5% 기준에서 p-value가 0.05보다 높으므로
귀무가설을 채택하게 됩니다.
p값(p-value)은 검정통계량 값에 대해서
귀무가설을 기각하기 위한 최소한의 유의수준을 뜻합니다.
즉, 유의수준이 63.56% 정도는 되어야
귀무가설을 기각할 수 있으나,
유의수준을 5%로 정의했으므로,
귀무가설을 기각할 수 없습니다.
같은 맥락에서,
p값은 귀무가설이 사실일 확률이라고도 볼 수 있습니다.
p값이 높아질 수록 귀무가설 발생확률이 높아지고,
p값이 낮아질 수록 대립가설 발생확률이 높아지기 때문입니다.
분산분석은 비교하고자하는 그룹들의 평균이
모두 같은지, 아니면 하나라도 다른지
여부만 알려줍니다.
따라서 분산분석을 통해
그룹들의 평균이 다르다고 판단된다고 하여도,
어떤 그룹이 다른지는 알려주지 않습니다.
이를 위해서는 분산분석의 사후분석이 필요합니다.
자주 사용되는 사후분석은 tukey의 hsd입니다.
여기서 tukey는 사후분석 방법을 개발한
John Tukey의 이름에서 나왔으며,
hsd는 honestly significant difference의 약자로서,
그룹간 진정으로 의미있는 차이를 뜻합니다.
파이썬의 패키지 활용을 위해 데이터를 가공하겠습니다.

tukeyhsd는 그룹과 각각의 값을 쌍(pairwise)으로 보고 분석합니다.

tukeyhsd는 결측치를 인지하지 못하므로,
해당 결측치를 삭제합니다.

pairwise_tukeyhsd 함수를 활용해서 사후분석을 실시합니다.
첫번째 인자는 데이터 값이 포함된 열을 입력하고,
두번째 인자는 각 데이터의 그룹명이 연결된 열을 입력하고,
세번째 인자는 유의수준을 입력합니다.

분산분석 사후분석은
각각의 그룹을 비교하여 보여줍니다.
A초등학교와 B초등학교 비교결과를 보겠습니다.
B초등학교의 평균은 A초등학교보다 1이 낮지만,
p값이 0.9로서 0.05보다 높으므로,
A초등학교와 B초등학교의 평균이 같다는
귀무가설을 기각(reject) 할 수 없습니다(False).
A초등학교는 C초등학교와 비교해도,
평균이 같다는 귀무가설을 기각할 수 없습니다.
따라서 다른 두 초등학교에 비해
평균운동시간이 더 길다는 A초등학교의 주장은
통계적으로는 맞지 않습니다.
결론적으로 평균운동시간이 더 길다는 이유로
다른 두 초등학교에 비해 학생들의 건강에
더 신경쓰고 있다는 A초등학교의 주장은
통계적인 측면에서 설득력이 부족합니다.
'분산분석' 카테고리의 다른 글
| [python/파이썬] 반복하여 여러 집단을 두 요인으로 분석하는 이원배치 분산분석 (0) | 2023.03.04 |
|---|---|
| [python/파이썬] 반복없이 여러 집단을 두 요인으로 분석하는 이원배치 분산분석 (0) | 2023.03.03 |