통계는 변수를 다루는 학문입니다.
원주율을 의미하는 π나, 자연상수를 의미하는 e와 같은 상수는 변하지 않는 수로서 의의를 지니지만,
통계의 본질은 변하는 수를 이해하고, 예측하는데 있습니다.
변수는 랜덤하게 발생하거나, 일정한 확률을 가지고 발생합니다.
일정한 확률을 바탕으로 발생하는 변수를 확률변수(Random Variable)라고 합니다.
주사위의 눈은 1, 2, 3, 4, 5, 6만 가능하며, 1.54와 같은 수는 나오지 않습니다.
이처럼 가능한 값들이 이산가족과 같이 흩어져 있는 확률변수가 이산확률변수입니다.
수학적으로 이산확률변수는 모든 원소들이 정수와 일대일로 대응하는 변수를 의미합니다.
주사위와는 달리 키와 몸무게와 같이 연속적으로 변하는 값들도 있습니다.
키의 자료값이 170센티미터, 180센티미터와 같이 떨어져 있는 것으로 보이지만,
실제 데이터에 들어갈 수 있는 자료는 170.000000001도 가능하며,
연속적으로 어떤 수치도 들어갈 수 있는 확률변수를 연속확률변수라고 합니다.
이산확률변수(Discrete Random Variable)
이산확률변수에 속한 값들이 띄엄띄엄 있을 때,
각각의 값들에 대해서 발생할 확률은 대응관계를 이루게 됩니다.

위 자료는 단순히 자료값이 10인 경우는 1개, 20인 경우는 2개, 30인 경우는 3개, 40인 경우는 4개로 보이나,
각각의 값들에 대해 일정한 확률을 지닌 이산확률변수들입니다.
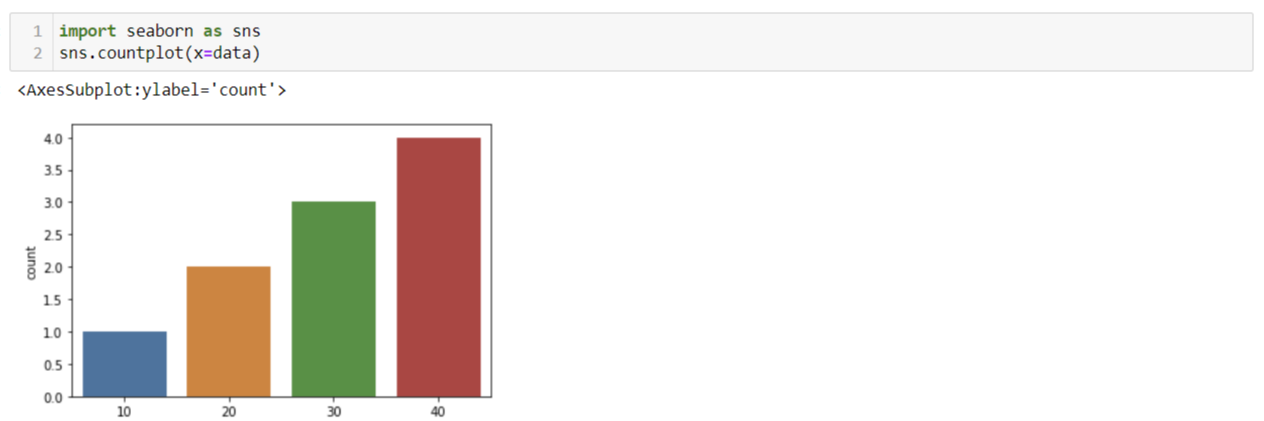
10이 발생하는 확률은 전체 데이터 개수 대비 1 / 10, 즉 10%이며,
20이 발생하는 확률은 전체 데이터 개수 대비 2 / 10, 즉 20%이며,
30이 발생하는 확률은 30%, 40이 발생하는 확률은 40%입니다.
이처럼 이산확률분포는 발생하는 확률이 항상 0% 이상 100% 이하이며,
모든 확률의 합은 100%, 즉 1이 됩니다.
이산확률변수와 이에 대응하는 확률을 정리하면 다음과 같습니다.

위의 데이터의 이산확률변수에 대해서, 확률에 기반하여 기대되는 값(기댓값)을 구하겠습니다.
기댓값은 이산확률변수의 각 값들과 이에 해당하는 확률을 곱한 후, 모두 합한 값입니다.

기댓값은 다음과 같습니다.

기댓값이 나왔으나, 기댓값만으로 이 데이터를 충분히 설명한다고 보기 어려우므로,
기댓값을 중심으로 자료값들이 흩어진 정도를 파악해 볼 필요가 있으며,
분산을 활용합니다.
분산은 편차를 활용하며,
편차는 각각의 데이터에서 기댓값을 뺀 것을 뜻합니다.
이 편차들을 모두 더하면 합이 0이 되므로,
분산은 각각의 편차를 제곱하고, 각각에 해당하는 확률을 곱한 후, 모두 더한 값입니다.

분산을 구하기 위해 다음을 입력합니다.

표준편차는 분산의 제곱근이므로 다음과 같습니다.

위 데이터에서 확률에 기반하여 기대되는 값은 30이며,
기댓값에서 기댓값에서 표준편차를 뺀 값인 20와, 기댓값에서 표준편차를 더한 값인 40 사이에서
상당수의 자료값이 분포되어 있다는 결론이 나옵니다.
수식에 기반하여 직접적으로 계산하였으나,
일반적으로는 식을 유도하여 다음의 공식을 더 자주 활용합니다.

유도된 식에 기반하여 분산을 계산하면 다음과 같습니다.
각각의 이산확률변수를 제곱하고, 이에 해당하는 확률을 곱한 후 모두 더합니다.
그리고 기댓값의 제곱을 빼줍니다.

이산확률변수의 기댓값과 분산에 기반하여 이산형 확률분포가 나옵니다.
이산형 확률분포에는
베르누이시행, 이항분포, 포아송분포, 기하분포, 음이항분포, 초기하분포 등이 있습니다.
데이터가 특정 이산형 확률분포를 따른다면,
해당 데이터의 특성을 보다 명확히 이해하고, 통계에 근거한 예측을 할 수 있습니다.
'기초통계 > 확률변수' 카테고리의 다른 글
| [python/파이썬] 연속확률변수 (0) | 2023.01.06 |
|---|