[python/파이썬] 포아송분포
변수는 랜덤하게 발생하거나, 일정한 확률을 가지고 발생합니다.
일정한 확률을 바탕으로 발생하는 변수를 확률변수(Random Variable)라고 합니다.
확률변수들이 모여 확률분포를 이루게 됩니다.
데이터의 확률분포를 알고 있다면,
일어날 수 있는 사건의 확률을 알 수 있고, 확률에 근거한 판단을 내릴 수 있습니다.
확률분포는 주사위처럼 결괏값이 떨어져 있는 이산형 확률분포와
키와 몸무게와 같이 연속적으로 변하는 값들로 이뤄진 연속형 확률분포가 있습니다.
이산형 확률분포에는
베르누이 시행, 이항분포, 포아송분포, 기하분포, 음이항분포, 초기하분포 등이 있습니다.
연속형 확률분포에는
균등분포, 정규분포, 표준정규분포, 지수분포, 감마분포, 카이제곱분포, F분포, t분포 등이 있습니다.
포아송분포(Poisson Distribution)
시간당 평균적으로 발생하는 사건의 횟수를 알고 있거나,
특정공간에서 평균적으로 발생하는 사건의 횟수를 알고 있다면,
우리가 궁금해하는 시간대에서, 우리가 궁금해하는 공간에서만 한정지어서,
우리가 예측하고 싶은 사건의 발생횟수를 확률적으로 알 수 있습니다.
한 시간에 두 번 발생하는 사건이 있다고 가정하겠습니다.
단순계산으로는 30분마다 한 번 발생할 것이며,
한번 사건이 발생하였으니, 30분이 지나 다시 사건이 발생한다고 예측할 수도 있으나,
이는 실제적으로 아무런 도움이 되지 않습니다.
사건 발생 후 1분이 지나 다음 사건이 발생할 수도 있고,
30분이 지나도 사건이 발생하지 않을 수 있습니다.
정확한 사건 발생시간은 예측할 수 없습니다.
다만 확률적인 예측은 가능하므로, 확률에 기반한 판단을 내릴 수는 있습니다.
바로 포아송분포를 활용하면 가능합니다.


한 시간에 두 번 발생하는 사건이 있으며,
30분 동안 두 번 발생할 확률은 다음과 같습니다.


수식에 이해하기 위해 직접 계산하여 확률을 구하였으나,
scipy의 poisson.pmf를 이용하여 간단히 구할 수도 있습니다.
pmf는 probability mass function의 약자로서,
지금처럼 사건의 발생 횟수라는 띄엄띄엄 있는 결괏값들을 구할 때,
특정 값에 대한 확률을 나타내는 함수를 뜻합니다.
poisson.pmf의 첫번째 인자는 우리가 알고자 하는 횟수를 입력하며,
두번째 인자는 기준시간당 평균발생횟수를 입력합니다.

30분 동안 두 번 '이하'로 발생할 확률을 구한다면,
0번 발생할 확률, 1번 발생할 확률, 2번 발생할 확률을 합하여 구합니다.


수식에 이해하기 위해 직접 계산하여 확률을 구하였으나,
scipy의 poisson.cdf를 이용하여 간단히 구할 수도 있습니다.
cdf는 cumulative distribution function의 약자로서,
2번 이하로 발생할 확률을 예로 들면,
0번, 1번, 2번까지의 확률을 누적하여 보여주는 함수입니다.
poisson.cdf의 첫 번째 인자는 우리가 알고자 하는 횟수 중 가장 큰 횟수를 입력하며,
두 번째 인자는 기준시간당 평균발생횟수를 입력합니다.

포아송분포는 개별 사건들이 서로 연관이 없이 독립적으로 발생하는 것을 전제로 합니다.
만약 첫번째 사건이 발생하고, 관련된 두 번째 사건이 발생하는 경우에는 푸아송분포를 따르지 않을 수도 있습니다.
포아송분포는 이항분포에서 유래하였으며,
만약 이항분포의 시행횟수가 상당히 크고,
발생확률이 0에 가까운 경우에는 포아송분포에 가까워집니다.
이항분포는 사건이 성공여부, 발생여부, 합격 여부처럼 두 가지 가능성만을 확인하는 분포입니다.
앞서와 같이 30분에 한 번 발생하는 사건의 경우, 발생 여부만을 확인하게 되며,
시간에 따른 발생횟수를 체크한다면 무한시 시행하는 것과 같습니다.
그 이유는 발생여부를 체크할 때 0.000001초와 같이 찰나의 순간마다 체크한다고 가정하기 때문입니다.
그리고 사건이 발생한 직후라도, 0.000001초 후에는 사건이 발생하지 않을 확률이 높으므로,
결과적으로 시간에 따른 시간별 발생확률은 0에 가깝게 됩니다.
따라서 희귀하게 발생하는 사건에 대해 포아송분포를 적용하는 경우가 많습니다.
포아송분포식이 지닌 특수한 구조를 이해하기 위해,
수학적으로 접근해보도록 하겠습니다.
포아송분포는 이항분포에서 유래하였으며,
이항분포의 식은 다음과 같습니다.
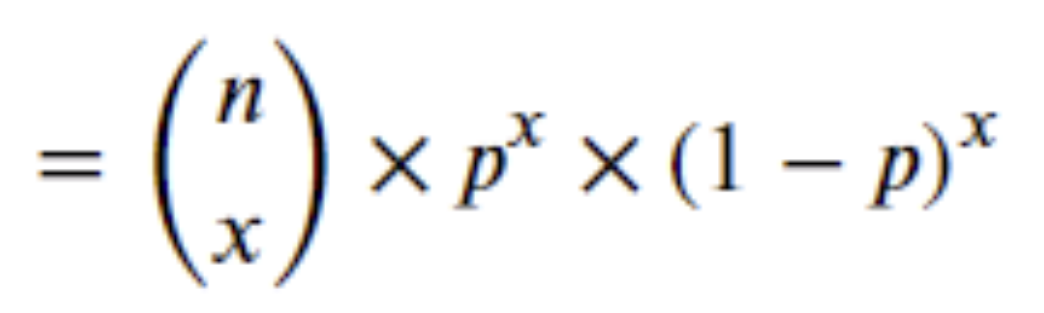
첫 번째 괄호 안의 n은 시행하는 횟수를, x는 우리가 알고자 하는 횟수를 뜻합니다.
괄호 안에서 n과 x의 의미는,
n번 시행했을 때, x가 나오는 모든 경우의 수를 말합니다.
예를 들어 세 번 중 두 번 성공하는 경우의 수는 다음과 같이 표현합니다.

모든 경우의 수를 나열하면,
성공, 성공, 실패 // 성공, 실패, 성공 // 실패, 성공, 성공하는 세 가지 경우가 있으므로,
이 경우 모든 경우의 수는 3입니다.
실제 계산과정은 다음과 같습니다.


다시 이항분포 식으로 돌아왔습니다.
p는 사건이 발생할 확률입니다.
(1 - p)는 전체 확률에서 사건이 발생할 확률을 뺀 것으로,
사건이 발생하지 않을 확률입니다.
푸아송분포에서는 기준시간당 평균발생횟수는 알고 있다는 전제하에 활용됩니다.
이를 람다라고 부르며, 람다는 이항분포에서 평균을 구한 결과입니다.
이항분포에서 평균(기댓값)은 시행횟수와 발생한 확률의 곱으로 나타납니다.

즉, 포아송분포는 이항분포에서 유래하였고,
이항분포에서의 평균은 시행횟수와 발생할 확률의 곱이며,
이 곱셈의 결과는 람다이므로,
포아송분포의 평균은 람다가 됩니다.
포아송분포의 분산을 구해보겠습니다.
이항분포에서의 분산은 다음과 같습니다.

포아송분포에서 시행횟수인 n은 시간의 범주내에서 계속 실행하는 것을 전제로 하므로,
결과적으로 무한대로 가게 됩니다.
p는 발생할 확률을 뜻하지만, 시간에 따른 확률이므로,
무한으로 나눠지는 시간 속에서 발생한 확률은 0에 가깝게 됩니다.
그 결과 포아송분포의 분산식은 다음과 같이 해석되어,
포아송분포의 분산은 람다가 됩니다.

즉 포아송분포의 평균도 분산도 모두 람다입니다.
다시 포아송분포식 유도로 돌아와서,
발생할 확률(p)을 람다를 이용하여 표현하면 다음과 같습니다.

최종적으로 이항분포의 식을 람다를 넣어서 표현해 보도록 하겠습니다.

각 항별로 살펴보겠습니다.

이 부분을 수를 대입하여 설명하면 다음과 같습니다.

람다가 포함된 이항분포의 식을 다시 정리하겠습니다.
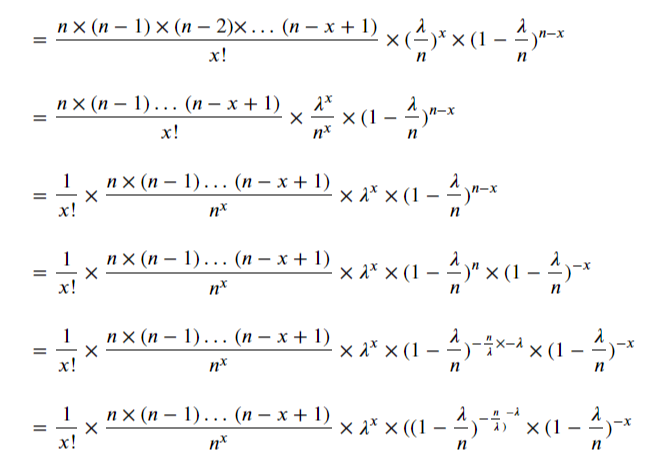
여기서 각 항을 들여다보면, 다음의 부분은 1이 됩니다.

다항식 나누기 다항식의 형태에서 n이 극한으로 가게 되면 분모분자의 최고차항의 계수만 비교하여 근사할 수 있습니다.
여기서 최고차항은 다음과 같습니다.

분모의 최고차항의 계수는 1이며, 분자의 최고차항의 계수도 1이므로, 최종적으로 1이 됩니다.
다시 식을 정리하겠습니다.
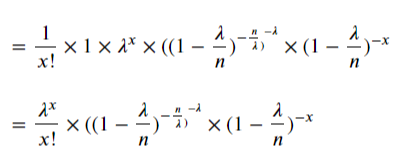
그 다음 살펴볼 항은 다음과 같습니다.
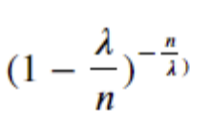
여기서도 시간에 따른 시행 횟수 n은 무한으로 갑니다.

이는 자연상수 e와 형태가 같습니다.

음수와 람다가 포함된 식이므로 e와는 다르다고 생각할 수 있으나,
n이 무한으로 가게되면 결과는 동일합니다.
그다음 살펴볼 항은 다음과 같습니다.

여기서도 시간에 따른 시행 횟수 n은 무한으로 가며 결과는 1이 됩니다.

람다가 포함된 이항분포의 식을 다시 정리하면 다음과 같으며,
포아송분포의 식이 됩니다.

포아송분포의 예제는 시간을 중심으로 살펴보았으나,
시간과 같이 무한히 나눌 수 있는 공간에 대해서도 발생 횟수를 확률적으로 예측할 수 있습니다.
포아송분포는 일반적으로 빈번하게 발생하는 사건이 아니라,
희귀하게 발생하는 사건에 대하여 예측력이 높다고 알려져 있습니다.